チュートリアル
Table of Contents
はじめに
美術館や博物館、公文書館などの機関が所蔵する絵画、古文書、彫刻、標本資料等の情報をデジタル化し、利活用しやすくするために整備されているのが、デジタルアーカイブです。デジタルアーカイブの構築に用いられる技術は、セマンティック・ウェブの技術を活用したものです。ジャパンサーチを使って要素技術を知り、実際に試してみましょう。
ジャパンサーチとは
ジャパンサーチは2020年8月に正式公開された、我が国が保有する多様なコンテンツのメタデータを、統合的に(横断的に)検索することができる、分野横断型統合ポータルです。2023年2月2日現在、197の連携データベースがデータを提供しており、メタデータ件数は約2800万件になっています。書籍、美術、公文書など、15分野に分けられており、それぞれの登録状況は以下のページから確認することができます。
ジャパンサーチには、大きく分けて以下のような機能があります。
- 検索機能
- ギャラリー:おすすめのコンテンツを展示形式で編集できる
- マイノート:気になったコンテンツをブックマークしておくことができる
- マイギャラリー:自分でギャラリーを作ることができる
ここでは試しに古地図を探してみましょう。古地図は「絵図」「国図」等の言葉で検索することもできますし、ギャラリーとしてまとめられたものもあります。
また、似ている画像を検索できる「画像検索」機能を試すこともできます。
画像データの活用:IIIF
それでは、個々の技術をみていきましょう。
IIIFとは、International Image Interoperability Framework の略で、日本語ではトリプル・アイ・エフと呼びます。(高精細な)画像や関連コンテンツを相互利用するために国際的に取り決められた枠組みです。IIIFは無料で自由に使うことができます。
IIIFを使うと、デジタル化された画像のリポジトリや、分散型のコンテンツネットワークを簡単に作成することができます。利用者が複数の機関のデジタルアーカイブを探し回ることなく、ひとつのタッチポイントでコンテンツが利用可能になるのです。IIIFでデータを公開するための技術的なハードルは低いので、オープンデータを推進しその恩恵を得るために、IIIFを利用して高精細画像を公開する美術館や博物館が増えています。
柔軟にコンテンツを公開できるIIIFの枠組みを使うと、違う美術館・博物館が所蔵している同じ作家の作品の高精細画像を比較したり、画像にアノテーションをつけることが簡単にできるようになります。
IIIFは複数のAPIとして提供されています。
- Image API(画像の操作を取り扱う)
- Presentation API(画像をふくむコンテンツ間の関係、アノテーションを取り扱う)
- Authentication API(コンテンツへのアクセス、認証を取り扱う)
- Search API(コンテンツ内のテキスト資源を対象にした検索を取り扱う)
IIIF Image APIを使うと、URIを用いてリクエストする画像の領域、サイズ、回転、品質特性、フォーマットを指定することができます。なお、IIIF Presentation APIには、後述するJSON-LD形式が採用されています。
IIIFを簡単に理解するためには、ビューアーを使ってみるのが一番です。ビューアーとして、Universal Viewer [https://universalviewer.io/]、Mirador [https://projectmirador.org/]、IIIF Curation Viewer [http://codh.rois.ac.jp/software/iiif-curation-viewer/] などがあります。ジャパンサーチ上でもIIIFに対応した画像を閲覧できます。
ジャパンサーチにおけるIIIF
【IIIF対応のアイテムを探す】
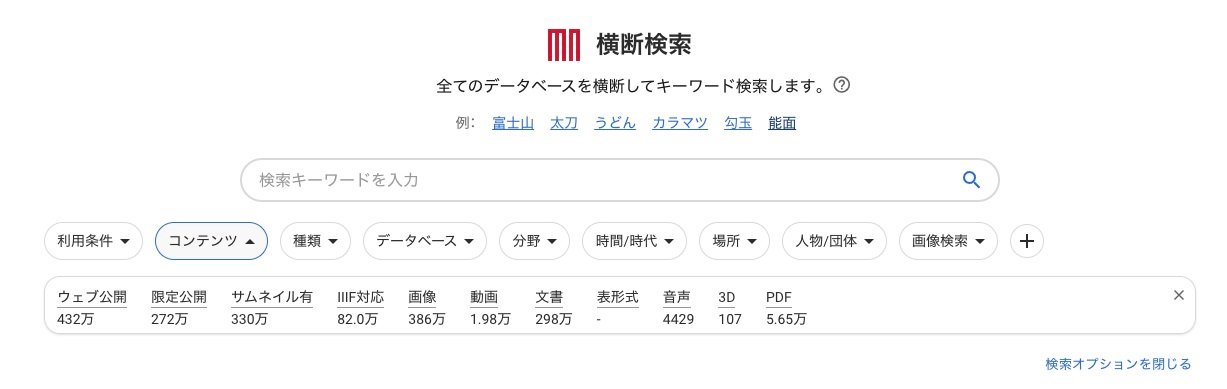
横断検索で「コンテンツ」をクリックし、「IIIF対応」を指定すると、IIIFに対応した資料を検索できます。
【IIIFを公開している主な機関を探す】
IIIFのサンプルを探すには、ジャパンサーチの資料詳細ページから「収録元データベースで開く」を押すと、IIIFを公開している機関のサイトを開くことができます。資料詳細ページを表示するには、検索結果一覧から閲覧したいアイテムを押します。

【IIIFをギャラリーで使う】
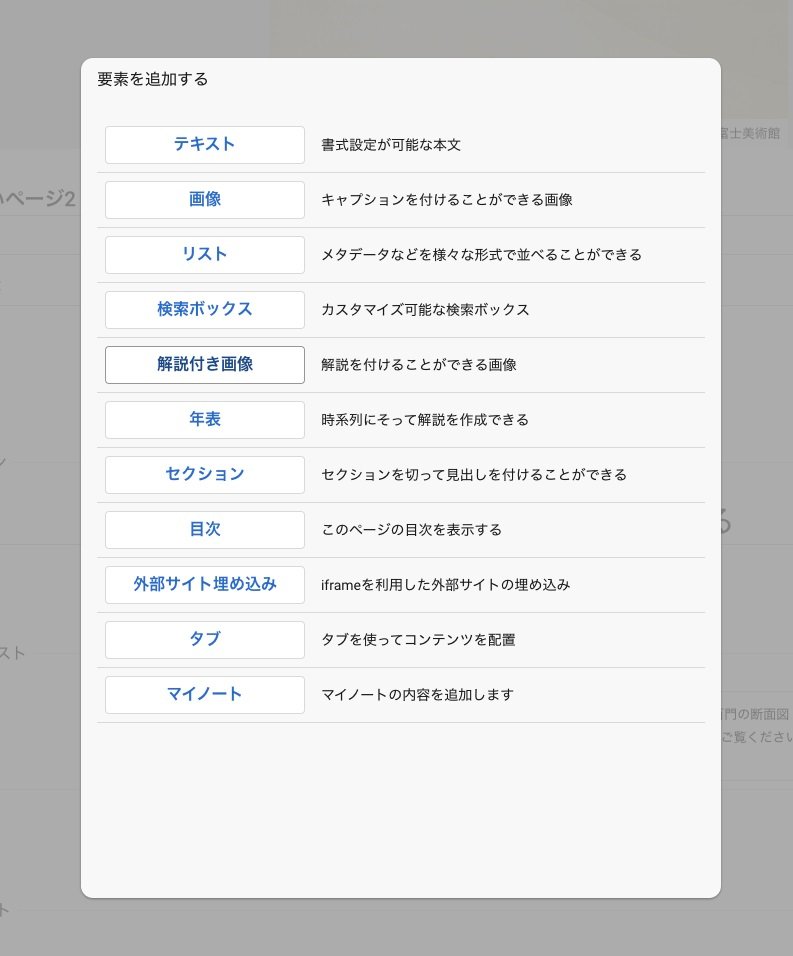
ジャパンサーチでは、オリジナルのギャラリーを作ることができます。ギャラリーの解説付き画像パーツでは、IIIFを使用しています。ジャパンサーチのマイギャラリーから任意のギャラリーを作成し「解説付き画像」を選んでみましょう。
メタデータの活用:RDFとSPARQL
ウェブの基本思想は、情報の内容(セマンティクス)と、情報の表現を分離できるようにする、というものです。たとえばウェブページは、文章構造(あるドキュメントを構成するそれぞれの要素の関係性)を機械的に解釈できるようにしていますが、見た目(デザイン)はCSSで分離されています(あるいは、スクリーンリーダーで音声読み上げをすることもできます)。
機械による情報の解釈可能性が担保されていることを、マシンリーダブル(Machine readable)といい、人による情報の解釈可能性が担保されていることは、ヒューマンリーダブル(Human readable)といいます。マシンリーダブル・ヒューマンリーダブルになっていることは、情報のアクセシビリティを成立させる2大原則といえるでしょう。文章構造の記述のことをマークアップといい、マシンリーダビリティを担保するために大切なのは、このマークアップの文法と解釈を厳密に定義することです。
定義の取り決めは、コンテンツの解釈方法が異なる複数の機関やコミュニティで、情報を相互に参照・利用する際にも役立ちます。事前知識に依存せずに、情報の持つ意味を明示的に伝達・利用できるようになるわけです。形式化は、大量の情報の管理や処理にも向いていますね。博物館や美術館では、ときに何万件、何十万件ものデータを処理する必要がでてきます。例えば、ジャパンサーチと連携している国立公文書館デジタルアーカイブでは、公開されているだけでも2023年2月2日時点で約400万件の情報が登録されていることが分かります。
博物館で取り扱われる情報も適切な構造化を施すことによって、様々なシーンや用途で利用することが可能になります。メタデータで取り扱う語彙や構造モデルは国際的に整備されており、よく知られているのはダブリン・コアやFOAF(Friend of a Friend)です。エンジニアであれば、Schema.orgをご存知の方も多いかもしれません。
ジャパンサーチにおけるメタデータ
語彙がある程度共通化されているとはいえ、メタデータの形式や整備状況は各機関の方針によって異なります。取り扱う資料の種類や量で、デジタル化の難易度が変わるからです。例えば絵画作品には作者がいますが、化石には作者はいません。1点ものの彫刻作品を写真に撮ることは比較的容易ですが、数百万件の公文書をデジタル化するのは容易ではありません。このことが、横断的にデータを取り扱う(検索・利用可能にする)ための障壁になりえます。
このため連携機関の作業負担を軽減しつつ、多種多様なメタデータの利活用を可能にするために、共通メタデータフォーマット(連携フォーマット/利活用フォーマット)が策定され、ジャパンサーチでの横断検索や様々なデータ利用を可能にしています。試しに、ジャパンサーチのAPIを見てみましょう。開発者向けの情報は、こちらにまとまっています。
- 利活用スキーマ概説:https://jpsearch.go.jp/static/developer/introduction/ja.html
- ジャパンサーチのSPARQLエンドポイント:https://jpsearch.go.jp/static/developer/sparql-explain/ja.html
- 簡易Web API 概説:https://jpsearch.go.jp/static/developer/webapi/
また、過去のイベントで多くのまとめやチュートリアルが公表されています。
RDFとSPARQL
データから、あるオブジェクトが特定の概念とどのような関係を持ちうるか(たとえば、ある概念に属しうるか)を判定することを推論といいます。マシンリーダブルになっているとは、推論可能であるといっても過言ではないでしょう。
ある情報を取り扱うための手法として、私たち人間が最も得意とするのは言語として分節化すること(ある体系のもとに概念を区別すること)です。たとえば、「果物」という体系に包含された概念として「りんご」を定義し、他の「果物」と区別して指し示しています。
このように、情報を取り扱うためには、体系的に分類(別の概念として区分すること)し、概念間の関係を記述していく必要があります。情報の機械的な処理には、分類体系と、関係を推論可能にするためのルール集が必要なのです。そのために、独自の意味(語彙)が定義された様々なデータを共通に取り扱うための言語がオントロジー言語(推論言語)、OWL(Web Ontology Language)です。
OWLは、用語・語彙、各要素間の関係を明確に表現するために用いられます。OWLを処理しやすくしたものがRDFです。RDFの基本構造は、データを「主語(S)」「述語(P)」「目的語(O)」の3要素で構成されるトリプルの組合せとして表現し、それぞれのトリプルを有向グラフで表すというものです。
「鸚鵡図(S)」の「著者(P)」は「伊藤若冲(O)」である
このように情報を表現すると、伊藤若冲が「著者なのか、依頼主なのか、コレクターなのか」迷うことはありません。RDFを用いると情報間の関係性、つまり意味を(形式的に定義された範囲で)記述することができます。OWLはRDFのトリプルの集合体で構成されます。
ただし、上記の例でいえば「著者」の定義をRDF自体は持っていません。なんらかの定義集(スキーマ)が必要です。特定の領域のための形式的な定義(RDFクラス)の集合体を示すのがRDFスキーマです。RDFスキーマには、基本クラスと基本プロパティ、サブクラスとサブプロパティが定義され、階層的に語彙を定義することができます。
トリプルを直接的に記述する構文が、N-Triplesですが、N-Triplesはヒューマンリーダブルではありません。これを読みやすく工夫したのがTurtleです。
ところでウェブアプリケーションでデータを取り扱う場合、メジャーなフォーマットになっているのがJSONです。RDFを取り扱うための形式として、JSONを拡張して、主語、URIとリテラルの区別を可能にしたJSON-LDが使われることが増えてきました。先程登場したIIIF Presentation APIにも、JSON-LDが使われています。JSON-LDの記述構文はTurtleに似ています。
RDFのデータ操作を行うための言語、SPARQLについても知っておきましょう。SPARQLを使うと、必須および任意のグラフ・パターンをその論理積と論理和とともに問い合わせることができます(他にも様々なサポートが可能です)。SPARQLクエリの結果は、結果集合またはRDFグラフとして返ってきます。SPARQLを実際に使って、その柔軟さを体感してみましょう。
SPARQLの実装例