SPARQLエンドポイントから取得できるデータについて ― 利活用スキーマ概説
1. 「記述情報」のURIと取得できるデータ形式
ジャパンサーチでは、登録されたメタデータの利活用、すなわち付加価値をもたらす二次利用を促進するために、多種多様なコンテンツの様々な形式のメタデータを共通の形式に変換し、RDF(Resource Description Framework)に基づいたリンクトオープンデータとして提供しています。この「共通の形式」を「JPS利活用スキーマ(JPS-RDF)」と呼び、JPS-RDF形式のデータを「利活用データ」と呼びます。
ある一つのコンテンツについての利活用データの集合を、「記述情報」と呼びます。ジャパンサーチに登録された各コンテンツの「記述情報」には、https://jpsearch.go.jp/data/で始まる一意のURIが付与されます。
- 例:https://jpsearch.go.jp/data/photo-00010_00558_0006
- (参考)「例」に示すコンテンツについての利活用データの集合をグラフで見る:PNG形式(.png)
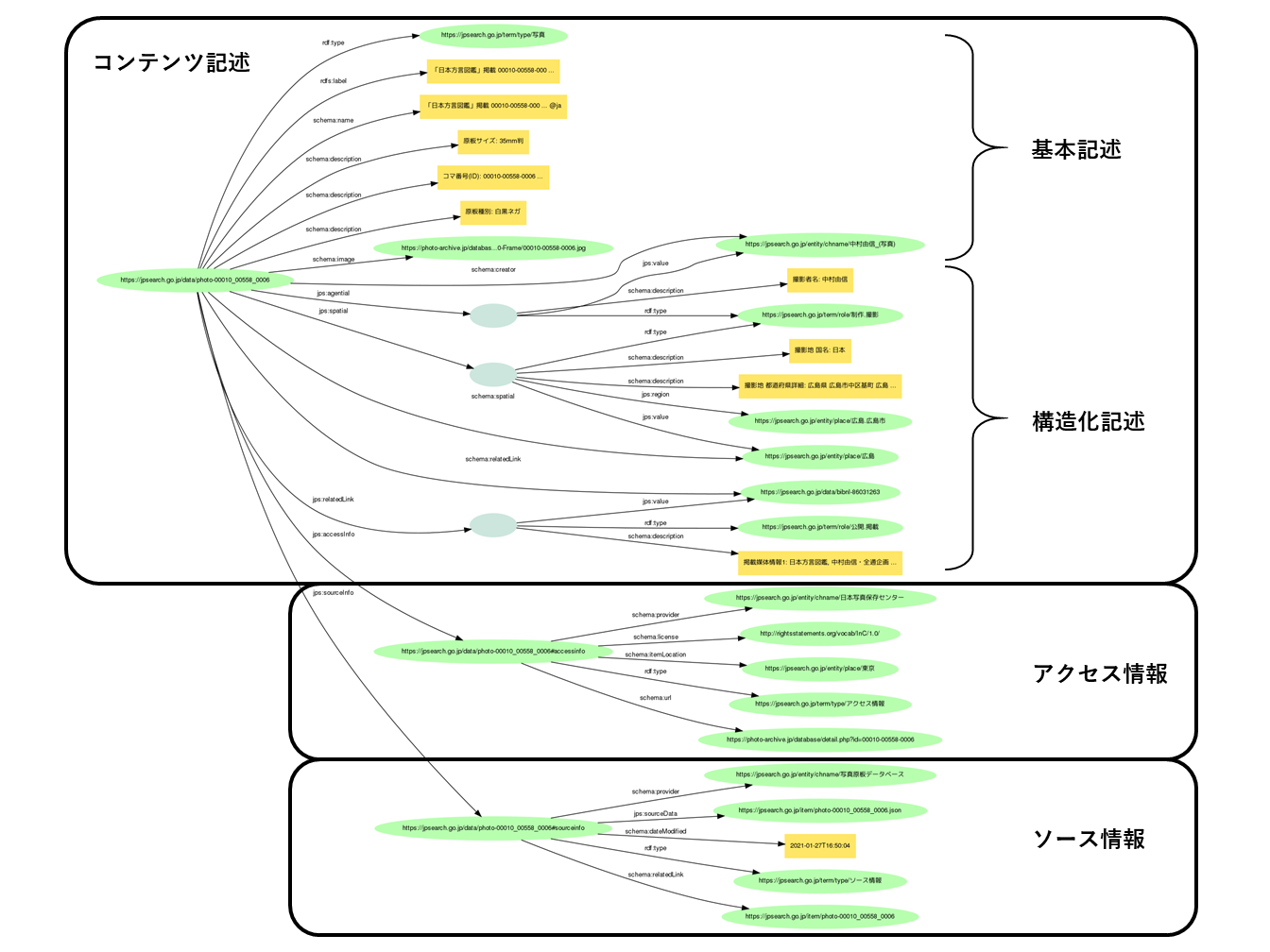{kind=link}
記述情報は、ブラウザからURIをリクエストすることによってHTML形式で確認できます。
また、記述情報のURIに拡張子を付けてリクエストすることによって、JSON-LD形式(.jsonまたは.jsonld)、RDF/XML形式(.rdf)、またはTurtle形式(.ttl)で取得することができます。さらに、拡張子なしのURIに対して利用アプリケーションがacceptヘッダを送信すれば、それぞれ適切な形式のRDFを取得できます。
- https://jpsearch.go.jp/data/photo-00010_00558_0006
- ブラウザからのリクエストによりHTML形式の結果が得られる。
- https://jpsearch.go.jp/data/photo-00010_00558_0006.json
- JSON-LD形式の結果が得られる。(拡張子を「
.jsonld」としても同じ結果が得られる。 - https://jpsearch.go.jp/data/photo-00010_00558_0006.rdf
- RDF/XML形式の結果が得られる。(拡張子を「
.xml」としても同じ結果が得られる。) - https://jpsearch.go.jp/data/photo-00010_00558_0006.ttl
- Turtle形式の結果が得られる。
- ※ Turtle形式の場合、データ内のIRIの非ASCII文字列がUnicodeエンコード(URLエンコードではなく
\uxxxx)されます。利用の際はご注意ください。
外部のアプリケーションから、利活用データを任意の条件で検索して利用したい場合は、RDFデータを利用するための標準クエリ言語であるSPARQLを用いて、SPARQLエンドポイントに問い合わせます。SPARQLをブラウザから利用しやすいSnorqlのインタフェースも用意しています。検索結果は、JSON、XML、Turtle等で取得できます。
2. データの変換と正規化
利活用データへの変換は、ジャパンサーチに提供されたメタデータのうち、APIによる提供に連携機関の承諾が得られたものについて順次行なっています。2026年3月現在、ジャパンサーチと連携する 310 データベース中 240 データベースに由来する 約2,980万件 のメタデータについて、利活用データに変換しています(約16億トリプル)。
利活用データでは、各機関が登録したメタデータ(ソースデータ)に含まれる「時間(いつ)」、「場所(どこ)」、「人や組織の名称(だれが/だれを)」の値を、できるかぎり標準的な表現に置換(正規化)し、ジャパンサーチに登録されたコンテンツ群を対象として、網羅性の高い検索結果の取得や、より精緻な条件による検索を可能にしています。値にはすべてURIを与え、正規化できたものはLODハブ(ウェブ上で他のデータから多くリンクされているURI)とリンクするようにして、ジャパンサーチ上のデータもウェブ上の他のデータから参照されやすくしています。
また、コンテンツの種別(絵画、彫刻、標本など)や作品の内容(主題、被写体、題材など)についての値(URI)を、ソースデータに含まれる情報を生かして定め、それを既存の分類体系や件名典拠の階層の中に位置づけるなど、コンテンツの発見機会を拡げるための工夫をしています。
- ジャパンサーチに登録されたコンテンツの種別(クラス):Excel形式(
.xslx) - ソースデータから利活用スキーマへのマッピング例:Excel形式(
.xslx) - SPARQLエンドポイント解説「2. いつ、どこ、だれ、なに」
- ジャパンサーチ名鑑-正規化名一覧 (外部サイト:The Web KANZAKI)
本文書において、説明のために用いる用語の定義は、特記する場合を除きISO5127:20171*1 、Linked Data Glossary*2 、及び「デジタルアーカイブの構築・共有・活用ガイドライン」(平成29年4月デジタルアーカイブの連携に関する関係省庁等連絡会・実務者協議会)*3 に依ります。
3. JPS利活用スキーマのデータモデル
JPS利活用スキーマのデータモデルは、大きく「コンテンツ記述」と「アクセス・ソース情報」という2つの部分から構成されています。「コンテンツ記述」はさらに基本記述と構造化記述の2つの部分を持ち、「アクセス・ソース情報」は、コンテンツのアクセスとその利用のための情報(アクセス情報)とジャパンサーチに提供されたメタデータ(ソースデータ)とその提供機関についての情報(ソース情報)の2つの部分を持ちます。これらの情報は、次の4グループのプロパティによって記述されています。
- データモデル略図:PNG形式(
.png) - プロパティのRDF表現:ShEx形式(
.shex) - 4. 利活用データで使用する語彙の名前空間 JPS独自語彙
3-1. 基本記述プロパティ
基本記述プロパティは25個あり、登録されたコンテンツの名称や言語、主題(テーマ)など、コンテンツの検索に広く用いられる情報を提供しています。基本記述プロパティには、ウェブ上のコンテンツのマークアップなどに用いられるSchema.org Vocabularyを用いて、幅広い利活用者にとって分かりやすいものとなることを目指しています。
- rdf:type
- rdfs:label
- schema:name
- schema:contributor
- schema:creator
- schema:publisher
- schema:temporal
- schema:dateCreated
- schema:datePublished
- schema:spatial
- schema:about
- schema:genre
- schema:category
- schema:identifier
- schema:isbn
- schema:issn
- schema:inLanguage
- schema:image
- schema:abstract
- schema:description
- schema:isPartOf
- schema:hasPart
- schema:relatedLink
- schema:exampleOfWork
- schema:workPerformed
なお、このほかにデータベースの追加に伴い、Schema.orgなどが提供する語彙を補助的なプロパティに用いることがあります。
3-2. 構造化記述プロパティ
コンテンツに関係する「時間(いつ)」や「場所(どこで)」「人や組織(だれが/だれを)」の情報、そのコンテンツが他のコンテンツの一部を構成する場合の「上位コンテンツ(何の一部か)」にあたる情報や、それ以外の「リンク関係(何と関連するか)」についての情報を、構造化して前項の基本記述プロパティとセットで提供しています。構造化とは、複数の要素に分解した情報をひとまとめに表現することです。
たとえば、「人」であれば、その名称を正規化した値だけでなく、元データで記述されていた名称や、その人がそのコンテンツにどのような関わり方をしたのか(「監督」なのか「出演」なのか)という役割の情報を、その人に関する情報の要素として提供します。「時間」であれば、年月日の情報とともに、何の時間か(「制作」された時間か「出土」した時間か)、またそれは、「何時代」とされる時期のものか、といった情報を提供しています。
こうした詳細な情報は、検索結果から必要とするコンテンツを識別する(見分ける)際や、複合的な条件で絞り込みを行う際に有用です。
JPS利活用スキーマには、構造化記述プロパティが5つあり、独自の語彙(接頭辞はjps:)でそれらを定義しています。(サブプロパティにはSchema.orgなどの既存語彙も用いられています。)
3-3. アクセス情報プロパティ
「アクセス情報プロパティ」は、コンテンツへのアクセスとその利用のための情報を構造化して提供しています。
ここでいう「コンテンツ」とは、「個々の文化・学術情報資源」のことでありデジタルコンテンツのほか、アナログの資料や作品も含んでいます。
たとえば、コンテンツが絵画である場合は、その絵画を保管している機関のほか、その絵画のデジタル化画像のURLなどがアクセス情報プロパティの要素になります。
3-4. ソース情報プロパティ
「ソース情報プロパティ」では、ジャパンサーチに提供されたメタデータ(ソースデータ)とその提供機関についての情報を構造化して提供しています。
メタデータをジャパンサーチに提供する連携先システムのURLのほか、ジャパンサーチのシステム内にJSON形式で格納しているソースデータのURLなどが、ソース情報プロパティの要素になります。
4. 利活用データで使用する語彙の名前空間
ジャパンサーチで独自に定義する語彙の名前空間は以下のとおりです。
| 語彙(Vocabulary Title) | 名前空間名(Namespace Name) | 接頭辞(Prefix) |
|---|---|---|
| JPS独自語彙 | https://jpsearch.go.jp/term/property# |
jps:
|
- JPS独自語彙:Turtle形式(
.ttl)
JPS独自語彙のほかに、使用する語彙の名前空間は以下のとおりです。
| 語彙(Vocabulary Title) | 名前空間名(Namespace Name) | 接頭辞(Prefix) |
|---|---|---|
| OWL Web Ontology Language | http://www.w3.org/2002/07/owl# |
owl:
|
| RDF Vocabulary | http://www.w3.org/1999/02/22-rdf-syntax-ns# |
rdf:
|
| RDF Schema | http://www.w3.org/2000/01/rdf-schema# |
rdfs:
|
| SKOS | http://www.w3.org/2004/02/skos/core# |
skos:
|
| Schema.org Vocabulary | http://schema.org/ |
schema:
|
5. 参考情報
-
- ジャパンサーチ利活用スキーマ(国立国会図書館ホームページ)
- 平成29年度のデータモデル検討時の資料
-
- ジャパンサーチ 非公式サポートページ for 利活用スキーマ(外部サイト:The Web KANZAKI)
- 平成29年度のデータモデル検討時の支援者である神崎正英氏(ゼノン・リミテッド・パートナーズ)によるジャパンサーチ利活用スキーマの応用や活用に関する情報掲載ページ
最終更新日: